
Lucidic's Evolutionary Simulations
Using Lucidic AI's auto-improvement algorithms (EvoSims), we achieved what took them months in less than 24 hours. We improved their baseline of 59% and increased it to 87.5% accuracy.
24 Hours
vs months of researcher's time
+23.3% accuracy
from 71% to 87.5%
< 0.1% of cost
$100k+ vs $200
Accuracy on Cresta FECT Using GPT 4.1-Mini
Baseline Prompt
59%
Cresta Optimized Prompt
71%
Lucidic Optimized Prompt
87.5%
Background
Cresta builds AI agents that help contact-center teams resolve issues faster and more consistently. By pairing real-time guidance with automated quality review, Cresta turns every conversation into actionable improvements for agents and operations. The company is grounded in a simple belief: quality and accuracy come first—because trustworthy answers drive better customer experiences, lower escalation rates, and measurable business value.
The Problem
Accuracy sits at the center of Cresta's business: higher agent accuracy drives better customer experiences and, ultimately, better outcomes for everyone involved.
Because this agent is core to the product, the system is highly sophisticated—multiple system prompts, a large toolset, complex evaluation frameworks, variations of data retrieval techniques, and more. Given that complexity, Cresta initially viewed improvements from an external platform like Lucidic AI working on untested data as unlikely.
To set a fair, easy-to-verify test, Cresta chose one well-defined part of their system: a single instruction ('prompt') used by the agent. They had already spent months improving this prompt and documented the method and results in a paper they published and presented at an AI conference.
Cresta then challenged Lucidic to optimize that exact prompt—using the same data and scoring rules—to see whether an automated approach could match or beat their published result.
Benchmarks to Clear
Accuracy
Baseline
Researchers raised accuracy from ~59% → ~71% on the prompt using their published method.
Target
Be close to 71% via automated prompt-only optimization to ensure high quality prompts.
Cost
Baseline
Verification costs ~$200 per prompt (10 runs at ~$20/run); at hundreds of iterations, API can be $10,000+.
Target
Cut verification spend by 70–90% using lower-cost verification passes, early-stop/sequential tests, cached eval contexts, cheaper models, and more efficient testing.
Time
Baseline
Manual tuning consumed multiple months of engineer effort (opportunity cost >$100k).
Target
Compress cycle time to <1 week with automated sweeps, adaptive sampling (more trials on promising variants), and one-click reruns with locked datasets/metrics.
Our Approach
The Lucidic Agent Optimizer transforms multiple system inputs—prompts, datasets, tools, evaluations, feature flags, and knowledge bases—into production-ready AI agents through automated, systematic optimization.

Our Methodology
Lucidic combines proprietary algorithms with advanced optimization techniques—including reinforcement learning, Bayesian optimization, and LLM-driven agentic pipelines—to systematically improve agent performance across the entire development and deployment lifecycle. Our approach doesn't rely on manual trial-and-error; instead, it automates the discovery of optimal configurations through intelligent search and evaluation.
For the Cresta FECT benchmark, we focused on a single instruction component. We decomposed the prompt into explicit, trainable parameters, including instruction wording, few-shot examples, ordering, guardrails, etc. and optimized them systematically under a fixed model configuration. The optimization follows a rigorous workflow: parameterize the agent components → search the configuration space using RL and Bayesian methods → evaluate performance on held-out data → keep the best-performing variants → improve iteratively until convergence. This structured process enables us to achieve superior results in a fraction of the time and cost of traditional manual optimization.
Results
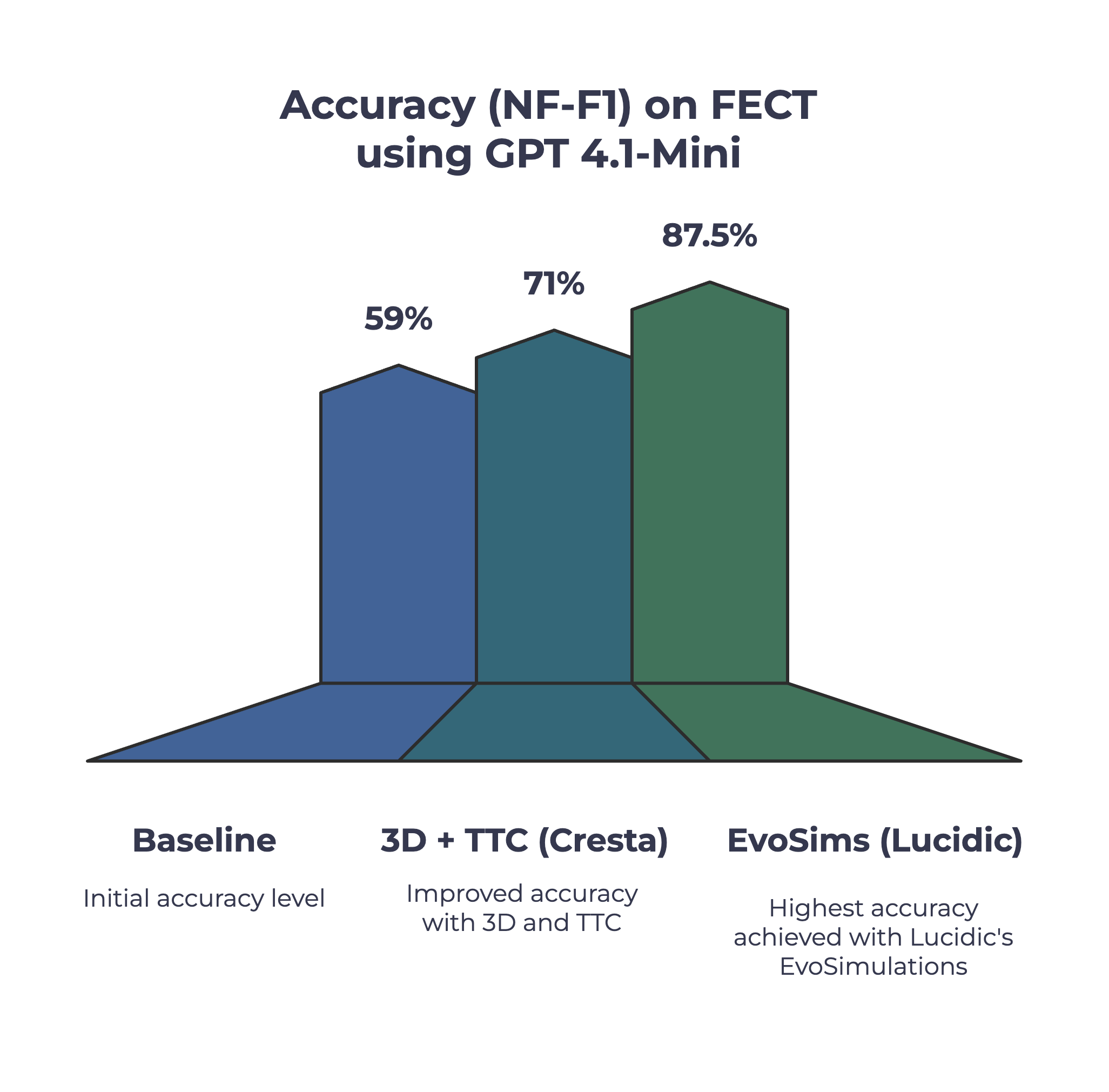
The Lucidic Difference
In less than 24 hours and less than $200, Lucidic's automated platform lifted performance on the evaluation dataset to 87.5% accuracy using GPT-4.1-mini, a low-cost model, surpassing the researcher-optimized benchmark of ~71%. Even against the team's top-of-line GPT-o1 configuration, Lucidic's GPT-4.1-mini achieved statistically higher accuracy at ~35× lower cost.
How Using Lucidic Could Help
Material accuracy lift
Better performance on real customer agents interactions and evaluations for them
Faster, cheaper iteration
Overnight optimization enables frequent retrains and rapid A/Bs without heavy engineering cycles
Operational & customer benefits
Fewer missed problematic conversations (fewer escalations), a lean QA model shifting to exception-based review, and reproducible evidence for risk/compliance/brand-safety that strengthens enterprise evaluations
Why It Matters
Measured against the stated targets (~71% accuracy, 70-90% cost reduction, and less than 1 week) Lucidic didn't just meet the bar, it cleared it decisively: 87.5% accuracy on a budget model, a full sweep at ~$200 (1% of cost), and less than 24 hours end-to-end. In practical terms, that's higher accuracy, orders-of-magnitude lower spend, and cycle times shrunk from months to overnight—all via agent-only automation that can be rerun and extended across adjacent components.
Beyond Prompt-Only Optimization
This case study demonstrates isolated prompt optimization. Lucidic's full platform optimizes the entire agent system:
• Data selection and corpus optimization
• Prompt library management and versioning
• Model and routing selection
• Tool integration and configuration
• Safety and rollout gates
• Continuous monitoring and improvement
Note: Optimizing just the prompt delivered outsized gains; optimizing the entire system typically yields further improvements.
Technical Appendix
Overview & Reference
Reference: github.com/cresta/fect
Metric: NF-F1 (Non-Factual F1), measuring non-factual claims detection accuracy
Dataset & Task
Given a contact-center transcript and a claim (e.g., "The issue was resolved"), predict True/False based on evidence. Stresses grounding, implicit evidence handling, and consistent judgments.
Understanding the Baseline
Baseline Prompt: A starting simple prompt which said to evalualte the claim against the transcript. It is found in the paper in the appendix. This was the prompt that Lucidic and Cresta started on and then iterated on.
3D prompt (Cresta Optimized Prompt): This final novel prompt, developed by Cresta, improved the agent's performance on their dataset by breaking down each claim using the 3D method, as detailed in the appendix of their paper.
TTC: Test-Time Compute is a concept that Cresta tested, representing the idea of allowing the model to generate additional reasoning tokens before producing a final answer. We implemented this by first having the model answer the claim with a reason, and then passing that response to another model to extract a true/false judgment.
What the FECT Dataset Is
FECT is a public benchmark released with Cresta that evaluates factuality judgments over contact-center conversations.
Input 1: Transcript: Anonymized/sanitized customer-agent call conversation
Input 2: Claim: Natural-language claim about the transcript (e.g., 'The agent offered a refund')
Task: Predict True/False whether the claim is factually supported by the transcript
Evaluation: Aggregate per-file/per-set metric: NF-F1 (non-factual F1), reported as Accuracy (NF-F1) for clarity.
Statistical Rigor
• n = 10 runs for all Lucidic results
• Sample σ = 0.0127 for main result
• 95% confidence intervals using t-distribution
• Differences expressed in percentage points and relative %
Data Hygiene
• No overlap between prompt examples and eval items
• Program-enforced + manual checks
• Artifacts available on request
Experimental Setup
• Model: GPT-4.1-mini, temp=0
• Optimized: Prompt + TTC only
• Iterations: 100 total
• Prompt Variants: ~60 explored
• Provenance: Started from baseline
• Parallel runs: Concurrent evaluation
• Batch sizes: 17–4,100 adaptive
• TTC: Used
• Finalists: n=10 reruns for CI
Our Results
GPT-4.1-mini + TTC:
87.5% NF-F1
n=10, σ=0.0127, CI: [0.8659, 0.8841]
Raw Accuracy: 96.2% overall, 97.8% F-F1
vs Paper Baselines
Cresta optimized prompt (GPT 4.1 mini): ~71% → Ours: 87.5% (+16.5pp, +23% rel)
Cresta baseline (GPT 4.1 mini): ~59% → Ours: 87.5% (+28.5pp)
Cresta o1: 86%±2% → Ours: 89.2±.45% (unoptimized)
Disclosures & Attribution
• Baseline numbers (59%, ~71%, 86%±2%) are cited from the authors' publication.
• Our materials (final prompt, compact runner, outputs) available on request.
• All trademarks belong to their owners.
